در باب ریختوپاشهای بیحساب دولتی سخن فراوان است؛ چنانکه سالهاست ضربالمثل تلخی میان اهل اقتصاد میگردد: «اگر ادارهٔ ریگهای بیابان را به دولت بسپاریم، کار به سهمیهبندی شن خواهد کشید». این حکایت، نمونهای تازه از همان داستان قدیمی است؛ روایتی از خرجکردن بیمهابای نهادهای حاکمیتی برای پروژهای که بخش خصوصی، با چابکی و تخصص بهمراتب بالاتر، میتواند از پس آن برآید و نتیجهای بس پربارتر تحویل دهد.
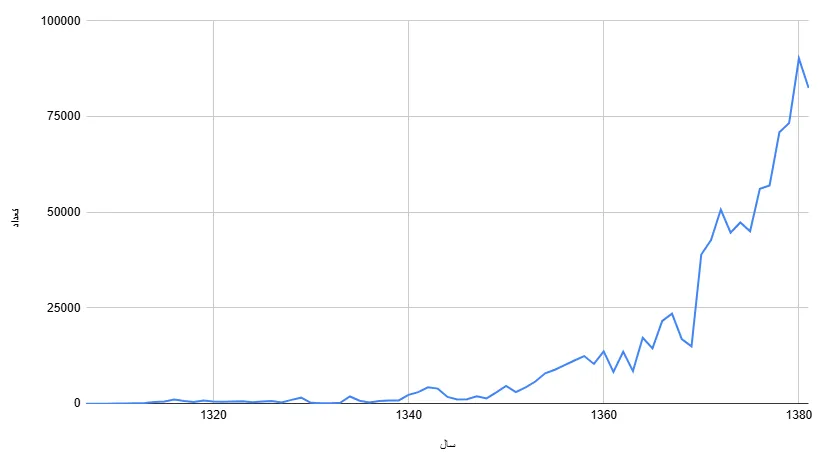
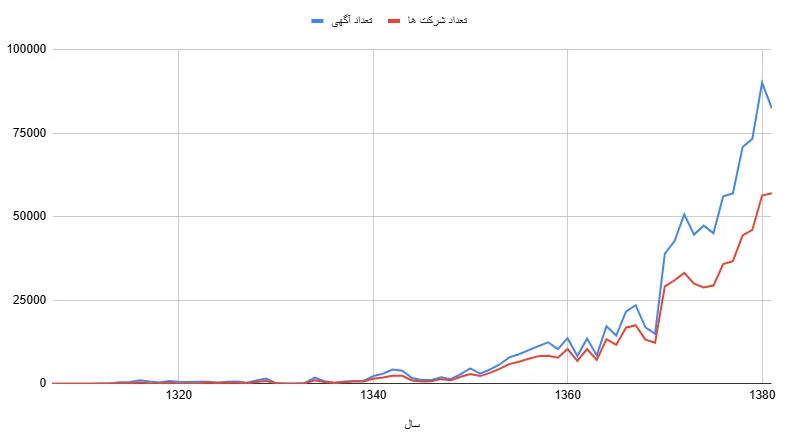
نخستین بار حدود ده سال پیش، در یکی از جلسات مشترک با مدیران «روزنامهٔ رسمی کشور» بود که نام این پروژه به میان آمد. «میخواهیم تمام شمارههای روزنامهٔ رسمی از سال ۱۳۰۷ تا ۱۳۸۱ را یکبار برای همیشه OCR کنیم و برای عموم دسترسپذیر سازیم». تجربهٔ چند سال کار جدی ما در حوزهٔ دادههای روزنامهٔ رسمی به ما نشان میداد که پروژه آنقدر هم برای کاربران حیاتی نیست و فقط بخش اندکی از کاربران به آن نیاز دارند؛ چرا؟ چون دادههای قدیمی، بهویژه آنهایی که پیش از دههٔ ۱۳۸۰ منتشر شدهاند، برای بخش ناچیزی از شرکتها ارزش عملی دارند. بیشتر کسبوکارهای قدیمی آگهیهای تغییرات خود را نهایتاً هر دو سال یکبار بهروزرسانی کردهاند و بنابراین به نسخههای تازهتری استناد میکنند. بااینحال همان حجم اندک دادهٔ مفید تاریخی همچنان میتواند در پژوهشهای حقوقی، دعاوی قدیمی یا مطالعات تاریخچهٔ مالکیت شرکتها گرهگشا باشد؛ در نتیجه پروژه کاملاً بیاهمیت هم نبود.
در همان روزهای نخست، صریحاً به مدیران روزنامهٔ رسمی پیشنهاد دادیم که خودشان را درگیر OCR نکنند؛ «داده خام را باز کنید؛ زیرساخت فنی، اسکریپتهای پردازش تصویر و فضای محاسباتی را ما حتی رایگان انجام میدهیم». منطق ساده بود؛ هر کس تخصص خودش را دارد؛ روزنامهٔ رسمی تولیدکنندهٔ محتواست، ما متخصص تبدیل و غنیسازی داده. ولی این تفکیک نقش ظاهراً مقبول واقع نشد و پیشنهاد ما رد شد.
وقتی دیدیم درِ مشارکت فنی بسته است، پیشنهاد تجاری مشخصی ارائه کردیم؛ انجام کل پروژه با مبلغی در حدود ۲۰۰ میلیون تومان (سال ۱۴۰۱). نمیدانیم پشت پرده چه گذشت، اما بعدها شنیدیم پروژه با قراردادی یک میلیارد تومانی به شرکتی فعال در حوزهٔ هوش مصنوعی واگذار شده است. برای اطمینان از صحت این موضوع چند بار از طریق «سامانهٔ دسترسی آزاد به اطلاعات» درخواست مستندات کردیم؛ بالاخره بعد از چندین بار پیگیری متن قرارداد برای ما ارسال شد. در قرارداد ارسالی نام پیمانکار درج نشده است و مبلغ قرارداد یک میلیارد تومان است.

تصویر قرارداد روزنامه رسمی کشور به مبلغ 1 میلیارد تومان
نتیجهای که امروز در وبسایت رسمی پروژه میبینید، متأسفانه با وعدهها نمیخواند و یک فاجعه تمام عیار است. موتور جستجوی سایت عملاً کارکرد خاصی ندارد؛ با وارد کردن نام یک شرکت، صرفاً تعدادی تصویر بیربط نمایش داده میشود و اگر تاریخ دقیق انتشار آگهی را ندانید، یافتن سند تقریباً ناممکن است. نمونهای دیگر از پروژههای دولتی که نه گرهای از کار مردم میگشاید و نه پاسخگوی وظیفهٔ حاکمیتیشان است. یک رفع مسئولیت تمام عیار بدون رفع نیاز کاربر!
اهمیت نسبتاً پایین این پروژه برای اکوسیستم کسبوکار ما را متقاعد کرد که آن را با کمترین هزینهٔ ممکن و بهعنوان یک تمرین مهندسی پیش ببریم. برای فاز استخراج داده، با مهندس وحید باقی وارد همکاری شدیم. ایشان ظرف کمتر از دو هفته، کل فرآیند خزش ماشینی (Crawling) وبسایت روزنامهٔ رسمی و تفکیک باکسهای آگهی را بهطور کامل انجام داد. همهٔ آگهیها را به شکل ساختیافته دریافت کردیم و کد مربوطه را نیز به صورت متنباز منتشر کردیم تا جامعهٔ توسعهدهندگان از آن بهره ببرد. حقالزحمهٔ ۲۰ میلیون تومانی مهندس باقی را با رضایت کامل پرداخت کردیم؛ سرمایهگذاری ناچیزی نسبت به ارزشی که خلق شد.
پس از آن تنها گام باقیمانده تبدیل تصاویر به متن بود. از میان سرویسهای OCR موجود، «Scanify» را برگزیدیم؛ برای چهار میلیون درخواست OCR، رقم ۳۰ میلیون تومان پیشنهاد دادند و در قبال درج نام سرویس در وبسایت ما، همان مبلغ را تثبیت کردند. یکپارچهسازی API آنها با سامانهٔ ما بدون دردسر انجام شد و بهسرعت فرآیند تبدیل آغاز گردید. در گام آخر هم متنهای OCR شده را با نام و شماره ثبت شرکتها تطبیق دادیم و در سایت قرار دادیم.
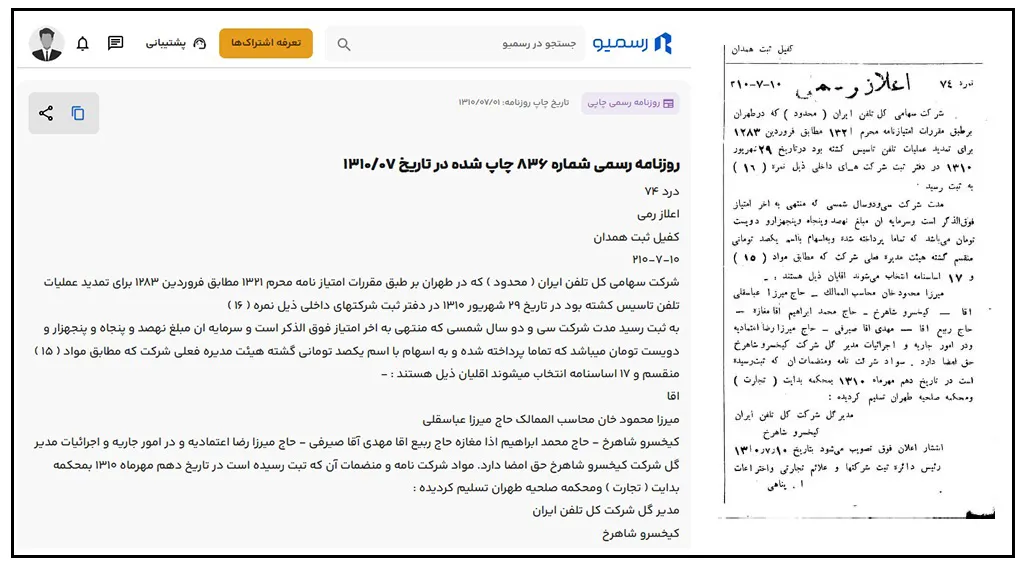
امروز یک خروجی واقعاً قابل اتکا در اختیار داریم. کافی است نام هر شرکت را جستوجو کنید؛ تمام آگهیهای قدیمی ثبتشده در روزنامهٔ رسمی بههمراه نسخهٔ تصویری و متن استخراجشدهٔ آن در دسترس شماست. میتوانید بهسادگی اسکرول کنید، فیلتر زمانی بگذارید و در بخش آگهیها، نسخهٔ چاپی و دیجیتال هر اعلان را کنار هم ببینید؛ آنگونه که از ابتدا وعده داده شده بود اما هرگز در سامانهٔ رسمی محقق نشد. این اطلاعات بدون هیچ محدودیتی در اختیار شماست.
تجربهٔ ما نشان میدهد که راه برونرفت از این چرخهی هزینههای بیثمر، چیزی جز شفافسازی و واگذار کردن کار به اهل فن نیست. هر بار که دادهٔ عمومی از چنبرهٔ انحصار حاکمیتی رها شده، جامعهٔ پژوهشی و کسبوکاری چند قدم جلوتر رفته است؛ این بار هم مستثنا نیست. ما دستاورد خود را چه کد، چه دادهٔ پردازششده در معرض استفاده و نقد همگان گذاشتهایم تا نشان دهیم خدمات باکیفیت الزاماً نیازمند قراردادهای میلیاردی و سازوکارهای پرهزینهٔ دولتی نیست. امید داریم نهادهای حاکمیتی نیز با احترام به تخصصها، نهتنها فرایندهای مالی چنین پروژههایی را شفاف کنند، بلکه با گشودن کامل درهای داده، مسیر بهرهمندی آحاد مردم و پژوهشگران را هموار سازند؛ آنگاه است که سرمایهٔ عمومی واقعاً به سرمایهٔ اجتماعی بدل میشود، و چرخهٔ دانایی این سرزمین، بهجای توقف در اتاقهای بوروکراسی، در زیستبوم پرتحرک نوآوری به گردش درمیآید.